
项目中需要使用 DAG 结构表示离线任务、数据源血缘关系及数据流向,采用 MySQL 来存储 DAG 数据结构并完成增删改查等常规功能。这里对 MySQL 存储、操作、遍历 DAG 图的方法进行记录。
这部分内容部分参照了《Designing Data-Intesive Applications》书中对于图状数据模型的描述。
名词解释
- DAG:有向无环图,包含节点(Vertex)和边(Edge)。
数据模型
需要两张表存储 DAG 的结构信息,节点表(vertex)和边表(edge)。
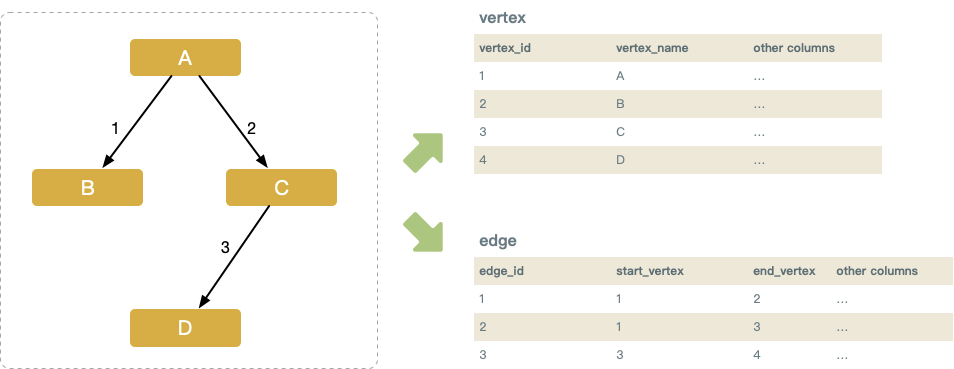
Insert
新增节点,在节点表和边表中新增相应记录即可。
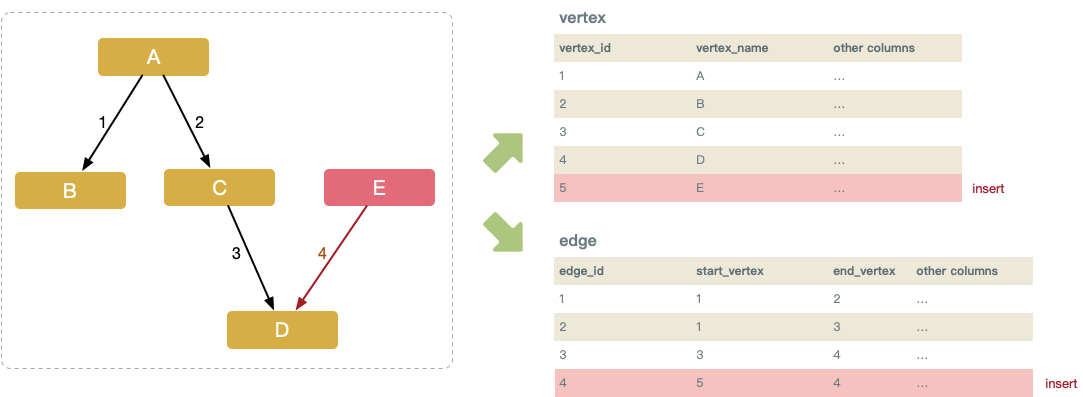
Delete
删除节点,节点记录以及与其关联的边记录全部删除。
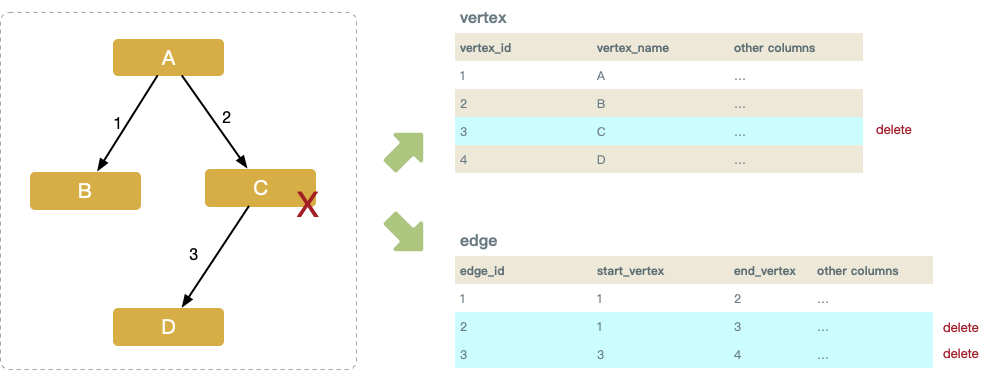
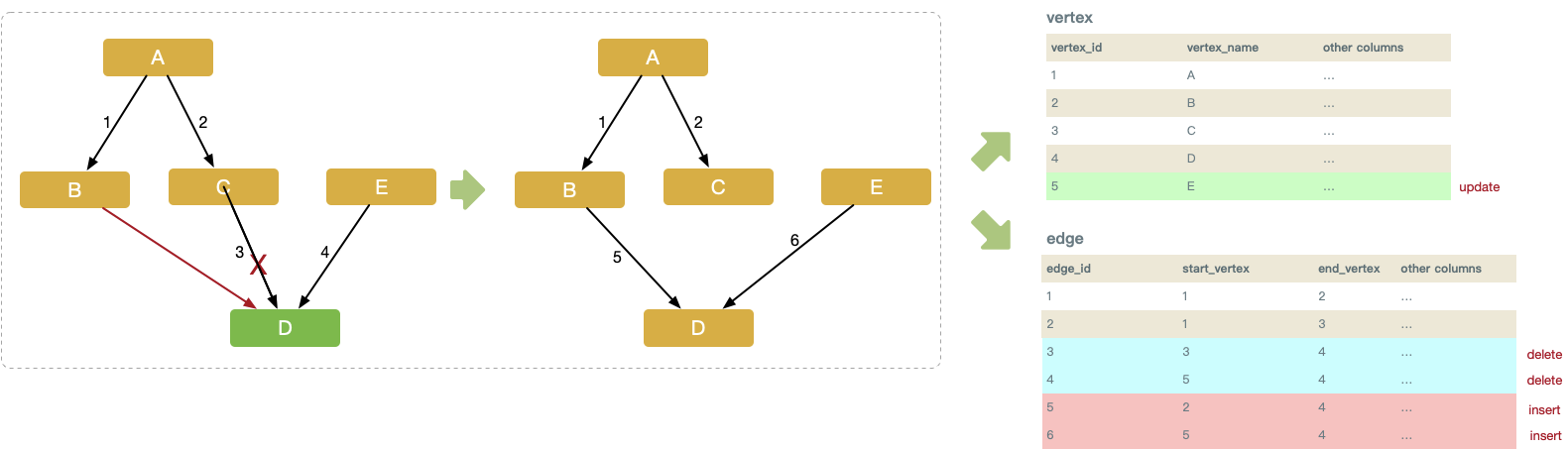
Update
编辑节点,对于节点本身的变更,对节点表相应记录 update 即可。涉及边的调整,比较简单的方式是先将所关联的边全部删除,再重新创建,并引入事务保证其原子性和可见性。
Get
对单一节点进行 DAG 构建,需要根据查看出度/入度以及拓扑深度对拓扑进行递归遍历。由于 MySQL 8+ 才有递归查询语法支持,所以只能在代码中实现递归逻辑。这里以查看入度(向上遍历)为例。
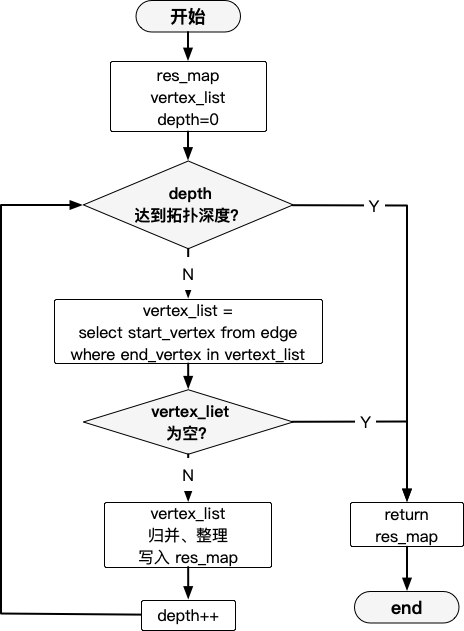
额外考量
基本逻辑确定后,需要结合具体业务分析需要调整和注意的 case。
1.节点自依赖
节点自依赖实际上破坏了 DAG 的模型(因为形成了环),要支持这种场景,可以将自依赖看做正常的边(start_vertext 和 end_vertext 相同),在节点遍历时如果碰到自依赖的边,不要将其压入递归队列中继续遍历即可。
2.循环依赖
节点间接引用了自身,同样属于破坏 DAG 模型,但与自依赖(直接引用自身)不同,这种场景一般都是需要避免的。 一般做法是在节点变更操作(Insert、Update)之前进行循环依赖检查,即先将节点的完整 DAG 构建出来,如果 DAG 中不包含要新增的节点,则可以进行操作。
3.线程安全
MySQL 数据模型将整个 DAG 的信息分散在了不同记录中,而且这些记录之间只能逐层识别关联,无法利用数据库事务做到隔离。 因此,需要借助锁实现线程安全,但锁的粒度需要和数据的预先分组相同,在我的项目中,任务在不同业务组中完全不可见,任务之间不能跨业务组建立关联,因此我的锁粒度就是业务组级别。 最坏的情况是,如果你不对这些数据进行分组,系统中同时只能发生一个 DAG 操作。
参考资料:
(End)