 先说点废话,已经三个多月没有更新博客了,原因是换了份工作,从准备、面试到最终入职也折腾了蛮久。结果还是理想的,拿到了几家一线厂的 offer,最终选择了百度(虽然在走下坡路,但怎么说也是国内一流大厂)。工作内容也终于逃离了业务,转为了中台赋能,平台开发,随之而来的是工作方式上的转变,也在慢慢适应。
先说点废话,已经三个多月没有更新博客了,原因是换了份工作,从准备、面试到最终入职也折腾了蛮久。结果还是理想的,拿到了几家一线厂的 offer,最终选择了百度(虽然在走下坡路,但怎么说也是国内一流大厂)。工作内容也终于逃离了业务,转为了中台赋能,平台开发,随之而来的是工作方式上的转变,也在慢慢适应。
说回正题,我所在的组定位是数据中台,服务于两百人的业务团队,有自己的数据平台,也承担一部分离线数据分析的职能,刚入职为了熟悉业务被安排两个 BI 相关的需求,这里谈谈这一个月数据开发的一些感悟。
数据开发是在做什么
大数据是近些年很火的 topic 之一,由此各个大厂也诞生了自己的数据中台,为业务方提供数据支撑。简单来看,数据中台主要有下面几方面的只能。
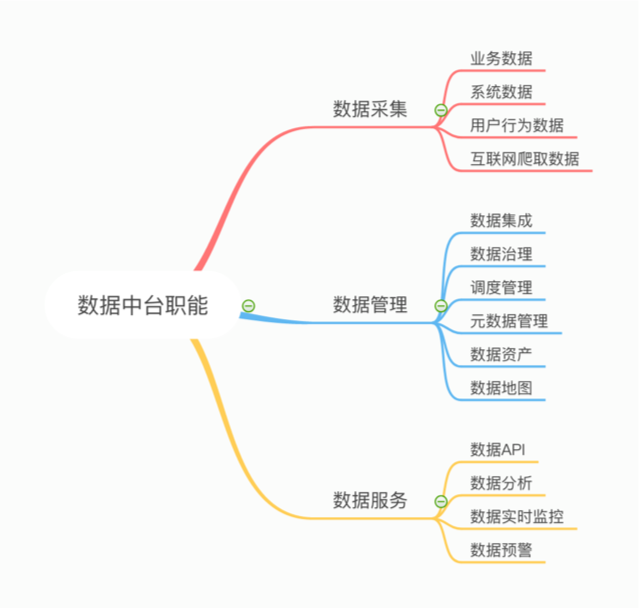
为了满足这些职能,会有数据平台(一般为企业级)提供诸如任务调度管理、元数据管理的只能,数据开发或 BI 分析人员就在数据平台的基础上完成数据接入、数据计算、结果导出的工作。
当然上面只是基础,数据开发人员真实的一天是怎样的呢?新业务上线,需要业务的流量、收益、转化率统计报表,PM 找到你,数据开发流程就此展开:
- 数据接入:首先你要找到业务方的开发人员拿到这些数据源,可能是 DB、日志、消息或者其他,将这些数据源配置录入现有数据平台并根据需求创建同步任务(实时流/增量离线/全量离线/单次导入),数据接入完成。
- 对齐口径:有了数据源,你还要和业务方沟通如何通过这些数据源里的数据获取报表信息(比如 DB 字段、日志规范等)。
- 数据计算:有了口径信息,进入开发阶段,数据开发一般是 Spark 脚本或 SQL,这时需要在平台上创建多个任务并设定好依赖关系,调试跑通,开始例行。这中间可能会有中间结果,一般选择储存在平台的 hive 表中。
- 数据导出:有了数据产出,根据需求不同确定产出方式,直接推数到业务 DB,或自己建立数据服务,提供不同纬度的数据查询(OLAP),测试、上线。
- 数据校准:QA 一般无法评估数据的准确性,这时需要 PM 在上线之后观察几天的数据产出是否符合认知,如果存在偏差需要对口径进行修正后重新上线。
到这里,一个数据开发需求就完成了。数据开发这东西,虽然看上去高大上,但实际做起来会感觉,接入、口径对齐基本都是沟通成本,而开发 Spark 和 SQL 学习成本也很低,经验的积累也仅仅限于熟悉流程、 Spark API 和 SQL 语法,难怪业内许多数据开发工程师自嘲为「SQL Boy」(/鬼脸)。
吐槽归吐槽,上面说到的东西确确实实是数据开发中的一些问题,所以如果之前没接触过大数据相关的东西,可以尝试尝试拓宽自己的知识广度,但是长期来看,成长性确实不堪,甚至不如业务开发。
这里说的仅仅是数据开发,数据平台开发完全是另一个方向了,之后会有篇文章介绍相关的内容。
虽然个人对数据开发的工作看不上眼,后面也不会继续做这个方向了(万幸),但这次短暂的数据开发体验倒是有不少其他维度上的收获。
重新审视数据模型
说来奇怪,数据建模本该是仔细设计的东西,但之前业务开发中经常被我忽略,是很么导致这个退步,反思原因主要有两点:
- 之前的开发模式下时间压缩的很紧,业务和与其他方交互的方案很重,很难做数据字典的设计。
- 直接简单的数据建模短期内不会显现劣势,就像烂代码只有当系统复杂到一定程度才会觉得不能忍受一样。
当然,不管哪种都是自己的问题。最开始接到报表需求的时候,我的数据模型就直接了当,报表表头就是我的表字段,加上时间维度,完事。当然,这个方案在评审的时候立马被拍死了,「报表新增一列你该怎么办?」一句话就被问住,现在想起来还不禁会脸红,软件设计不应该是面向需求设计,而应该是面向需求变更设计,这么简单的道理却在不经意间被遗忘到了脑后,当然你可以选择在报表变更时新增字段,但加字段永远是最愚蠢的方式,就数据开发来讲,新增字段不仅是重新开发数据脚本那么简单,还会带来历史数据正确性的问题,而回溯大数据量的数据任务带来的时间和资源成本有时候是不能接受的。
那应该怎么做呢?你把 MVC 忘了吗?
其实软件开发的思想在很多领域都是相通的,MVC 不仅是 web 领域的经典模型,也适用于数据开发场景。对于报表这个需求来讲,报表如何呈现只是 View 层,而数据字典就是 Model 层,中间的 Controller 其实可以做很多事情。这么一想事情简单了许多,模型抽象在代码中经常会做,用在建表上也是一样的道理,尽量将不变的东西抽像出来,变化的部分又可以拆成两类,一类是指标,一类是维度,维度可以新增枚举值,而指标就是简单的结果数据,最终的数据字典也就出来了。这样新增一列也是在指标项中新增枚举值,除非新增新的指标(这才是真正意义上的产品变更),否则不需要重新开发。
如何应对复杂度
第二个需求是对一个很复杂的数据统计流程的重构,流程数据源有十几张表,中间的任务不计其数,光梳理现有逻辑就用去好几天,由于任务多导致数据流维护成本极高,数据出现问题很难排查,而且一个环节出问题又会导致整个流程 Block,数据延迟产出,已经到了非改不可的地步,于是小组 Leader 牵头对整个数据流进行重构。
那如果是你你会怎么做呢?我肯定会很头疼,像是被强行喂屎。下面讲一下 Leader 的思路。
首先,造成数据流可维护性差的原因是什么?数据统计指标和维度多,造成数据源多且杂,但量多一定不是复杂度提升的直接原因,一定是数据量的增加暴露了设计上存在的问题。顺着这个思路,我们对任务的计算逻辑进行了部分梳理,很快发现了问题,整个数据流中存在很多重复计算,比如最简单的从广告落地页 url 关联创意 id 的逻辑就同时出现在了三个地方,其他计算逻辑同理。重复计算影响到计算逻辑变更时的复杂度和风险,如果计算逻辑存在偏差还会导致数据不一致,影响最终结果。
那如何解决重复计算的问题呢?继续分析为什么会有重复计算,因为每个数据源在计算统计指标的时候需要同时和维度进行关联,而维度是需要进行计算的,这个种情况换个说法叫做耦合。所以,既然维度和指标是耦合的,那将它解耦就解决问题了。所以我们顺着上面的思路,拿到报表的所有维度信息,看最小的维度信息是哪个,从哪里可以获得维度数据的关联,最终方案可以走通,我们新增了一张表专门储存维度信息的关联关系,这样,只需要得出源表的最小维度信息的指标数据,就可以通过维度表得到不同纬度的数据,维度关联也只需要计算一次,问题解决。
那还有其他问题吗?当然有,从源表到维度表的计算逻辑比较臃肿,源头分散不易维护。怎么解决呢?我们将源表到维度表的计算中间新增一步,进行不同纬度数据的整理,将结果存在对应的大表中(如商品大表、广告大表、订单大表等),这样,每种维度只有一个表,再计算维度信息也变得容易许多。
指标大表和维度表的出现无形之中为数据流划分了严格的层次,上层只可以访问同层和直接下层,在聚合最终结果前多了一层治理环节,每层的结构清晰分明,解决了可维护性和稳定性的问题。
当然,方案是 Leader 制定的,组内其他人包括我只是执行者。从 Leader 介绍他的排查思路,到最后的总体设计,还是学到不少东西。还是上面那句话,要尽量抽象不变的东西,这个需求中,维度信息就是不变的东西,广告的收益是每天都在变化的,但广告是从哪个创意来,创意又属于哪个订单,以及订单和商品的关联关系是不会变的,维度表相当于是储存了中间结果,减少了重复计算。
结语
这么看起来,很多东西确实是相通的,MVC 不仅是一个 web 模型,分层也不仅可以应用到代码架构,你需要有足够多的积累和敏锐的判断,才能洞察到这些东西。所以,如果你很不幸做了一个看起来不怎么样的方向,也别先着急抱怨抵触,好的思考和判断在哪个方向上都是可行的,用积累解决不同方向的问题是最好的个人能力的体现。
我始终认为,个人的成长其实分为两个方面,一个是技术能力,这个需要靠不断学习、消化、demo 实践来提高;另一个是对业务的理解和洞察,当然这个不是指熟悉业务,而是指应对不同业务场景的解决方案和思路,相比技术能力,这个只能靠在工作中不断思考和判断来提高,而这种能力的提高是一种全方位的思维方式的转变,这也是为什么即是应对复杂场景,有些人也能在短时间内找到合理的解决方案。
这次短暂的数据开发结束后,我发现自己之前的眼界被束缚了,幼稚的地方在于认为只有分布式、微服务才叫系统设计,只有代码才存在耦合和抽象。不过好在和优秀的人工作,才能慢慢发现自己的短板和局限,之后的学习也会继续围绕上面两个方面展开,之前比较侧重的是个人技能的积累,后面会更多的总结些工作上的思考和判断。
( End )