对 Redis 的原理与实现做个总结,大部分来自《Redis 设计与实现》一书。主要内容涉及 Redis 的持久化、复制策略、集群实现和事务。
过期时间与删除策略
在 redisDB 中用一个 expires 的字典保存设置了过期时间的键,val 指向过期时间,是一个 timestamp 对象。
删除策略:采用惰性删除与定期删除结合的策略。
- 惰性删除:当操作一个键时,如果过期就将其删除
- 定期删除:会定期,在规定时间内随机检查一部分键的过期时间,如果已过期就将其删除,有一个全局变量会记录检查进度。
持久化
Redis 的持久化有两种,RDB 和 AOF。
RDB 是压缩过的二进制文件,RDB 持久化既可以手动执行,又可以定期执行。Redis 提供两个命令进行手动 RDB 持久化:
SAVE:阻塞直到持久化完成BGSAVE:创建子进程进行持久化,父进程继续接受客户端请求
RDB 载入:在服务器启动时自动进行,但如果开启了 AOF 持久化,会优先使用 AOF 文件恢复数据库状态。
AOF 通过追加写入服务器的写入命令来进行持久化。通过下面三步进行:
- 命令追加:将命令写入 AOF 缓冲区
aof_buf中。 - 文件写入:在事件循环结束后将
aof_buf中的命令写入文件。 - 文件同步:调用
sync将文件进行同步,何时同步由配置决定,有三种方式,always、everysec、no。
重写机制:为了防止 AOF 文件过大,会创建一个子进程来对 AOF 文件进行重写,将同一个键多个操作的命令整合为一个命令。重写期间新接收的命令会写入 AOF 重写缓冲区。
事件
Redis 是一个事件驱动进程,本身是一个事件循环(loop)。存在两种事件:
- 文件事件:对 socekt 进行的操作,采用单 reactor 单线程模式创建文件事件处理器,监听多个 socket 文件描述符,根据 socket 所执行的任务分配不同的时间处理器。
- 时间事件:在特定的时间/周期进行的操作,维护了一个无序链表,每当时间执行器运行时,会遍历整个链表,查找已到达时间的时间并调用相应的事件处理器。
事件调度策略:
- 所有事件的处理都是同步、有序、原子的进行的,服务器不会打断事件处理,也不会对事件进行抢占。
- 多路复用 I/O 的 timeout 是由到达时间最接近当前时间的事件决定的。
- 时间事件的处理通常会比设定的时间稍晚一点,因为在事件处理过程中时间事件可能已经到达。
事务
Redis 的事务是指将多个命令打包,一次性、按顺序地执行多个命令的机制,在执行事务期间不会被其他请求中断。
事务的实现依靠一个命令队列来存放命令,在 Redis 中有个multiCmd类型的数组,保存了已入队命令的相关信息。命令以 FIFO 的方式进入数组。
Redis 事务的 ACID 性质:
- 原子性:Redis 不支持事务回滚,事务中的一条命令执行失败,Redis 会忽略这条失败的命令继续执行接下来的指令。
- 一致性:事务不会影响 Redis 的数据一致性。
- 隔离性:Redis 的单线程模型天然支持事务隔离。
- 持久性:Redis 的事务没有额外的持久化操作,由 Redis 的持久化配置决定。
复制
Redis 的复制功能包括同步 Sync 和命令传播 Command propagate来实现。
slave 对 master 的同步通过发送同步命令来实现,同步命令有两种:
SYNC:2.8 版本之前的命令,master 收到同步命令后会执行BGSAVE创建 RDB 文件,之后将 RDB 文件和缓冲区内的写命令发送给 slave。PSYNC:根据是否为第一次同步会执行完全重同步(相当于 SYNC)和部分重同步。
部分重同步由三个部分构成:
- master 和 slave 的复制偏移量:master 每次向 slave 发送 N 字节数据时,将自己的复制偏移量加 N,slave 收到 N 字节数据时,将自己的复制偏移量加 N。
- master 的复制积压缓冲区:master 维护了一个 FIFO 的队列,大小为 1MB。每次命令传播时会将命令写入队列,并为队列中的每个字节记录复制偏移量。
- 服务器的运行 id:master 和 slave 都有一个自己的运行时 id,slave 在重连同步时要判断是否是之前的 master。
PSYNC的调用过程:
- slave 向 master 发送同步命令,分为两种情况:
- 没有 master,会发送
PSYNC ? -1 - 有 master,会发送
PSYNC <runid> <offset>:offset 是 slave 当前的复制偏移量。
- 没有 master,会发送
- master 向 slave 回复,会有三种结果:
+FULLRESYNC <runid> <offset>:表示 master 会进行完全重同步,runid 是 master 的运行 id,slave 会记录这个 id,在之后的PSYNC命令中用到。+CONTINUE:master 会进行部分重同步,会发送 slave 缺少的命令字节。-ERR:错误。
命令传播:在同步结束之后,slave 与 master 进入命令传播阶段,master 会不断发送自己执行的写命令给 slave。
心跳:slave 会以每秒一次的频率,向 master 发送命令REPLCONF ACK <offset>,来检测连接状态和命令丢失。
Sentinel
Redis 的高可用决策策略是独裁式,使用哨兵 Sentinel(节点或集群)即充当了独裁者,来监控并收集 master 和 slave 的信息,并及时作出 failure detction 和 failover。
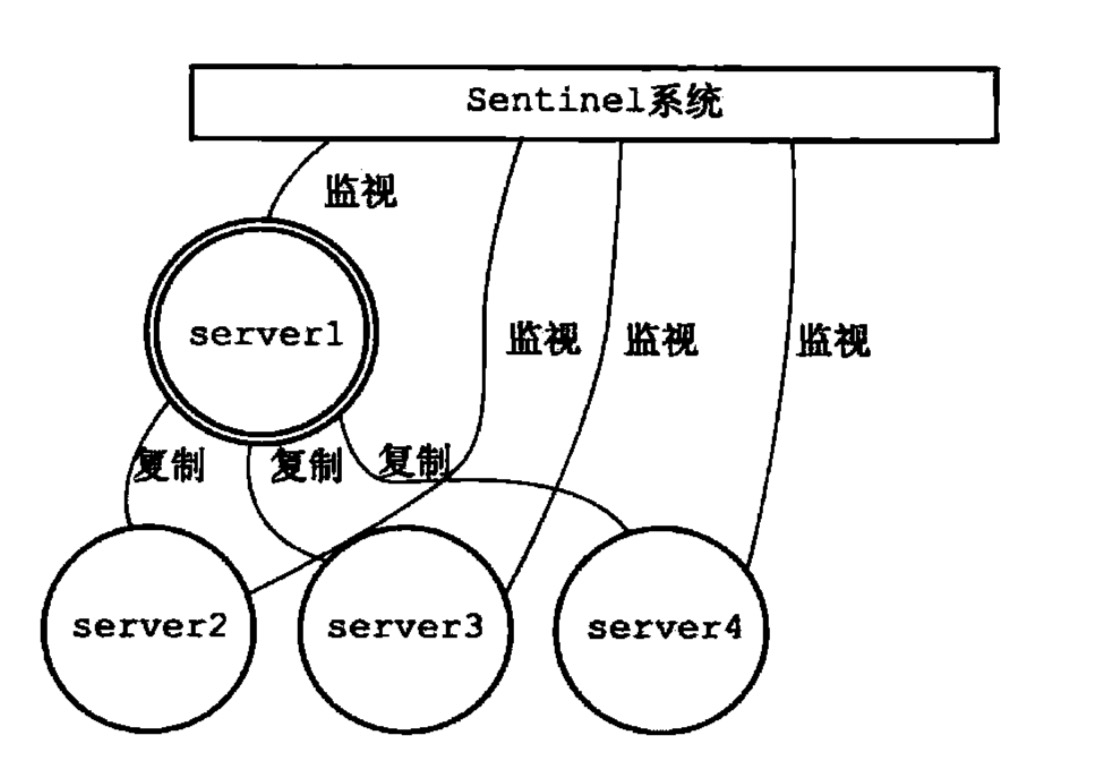
数据存储
Sentinel 用字典(哈希表)存储监视的服务器信息,所有服务器信息,包括 master、slave 以及其他的 sentinel 节点都是一个sentinelRedisInstance实例。Sentinel 节点在收到频道信息后会更新这些信息。
工作模式
- 创建连接:Sentinel 会分别与 master 和 slave 建立两个异步网络连接,命令连接和订阅连接。
- 获取服务器信息:以10s/次的频率通过命令连接向 master 和 slave 发送
INFO命令,获取服务器的拓扑信息以及 runid、slave 的复制偏移量等。 - 向服务器发送信息:以2s/次的频率通过命令连接向 master 和 slave 发送
PUBLISH __sentinel__:hello开头的命令,包含 sentinel 系统的信息和 master 服务器的信息。 - 心跳:Snetinel 节点之间,以及和 master、slave之间都会存在心跳,心跳的方式有三种:
- Ping:用来检测节点是否在线
- INFO:获取其他服务器信息
- 频道信息:更新监视的其他服务器的信息
failure dectation
Sentinel 通过两种步骤进行故障检测:
- 主观下线:Sentinel 会以默认 1s/次的频率向所有与它建立命令连接的节点发送
PING命令,并通过命令回复判断节点是否在线。当 master 节点在一定时间内没有返回有效回复,就判断 master 主观下线。 - 客观下线:一但一个 Sentinel 节点判断 master 主观下线之后,为了确定 master 真的下线,会向其他 Sentinel 节点发起询问,如果超过一定数量的节点(默认 n/2)都判断 master 主观下线,则 Sentinel 系统判断 master 客观下线,开始进行 failover。
automatical failover
在进行 failover 之前,Sentinel 集群会首先会选举出一个 Leader,由 Leader 选择一个 slave 将其作为新的 master,选举过程是简化版的 Raft 算法。
failover 的过程分为下面几个步骤:
- 从下线的 master 的 slave 节点里选出一个 slave,将其作为新的 master。
- 为其他 slave 设置新的 master 开始复制。
- 将下线的 master 设为新 master 的 slave,其上线之后开始从新的 master 复制。
集群
Redis 自带了分布式存储的解决方案,构建集群并对数据进行分片存储。
结构
Redis 的 cluster 是一个去中心的网络拓扑结构,每个节点都保存了其他节点的信息,任意两个节点之间都存在通信。
sharding
Redis Cluster 用槽指派来实现 sharding,Redis 一共设定 16834 个槽,所有的键值都属于槽内。每个节点通过ADDSOLTS设定自己处理的槽的范围,并广播给其他槽。节点在接收到客户端请求后,节点会计算键值对应的槽并判断是否是自己处理的槽,如果不是会返回一个MOVED错误指引客户端请求正确的节点。
reshard
重新分片命令会将一定数量的已指派的槽从源节点改为指派到目标节点,之后会将这部分槽位对应的键值对迁移到目标节点,在迁移过程中两个节点均不会下线或暂停服务。
单个槽的迁移步骤如下:
- 向目标节点发送命令使其准备好导入属于槽 solt 的键值对。
- 向源节点发送命令使其准备好属于槽 solt 的键值对进行迁移。
- 向源节点发送命令获得最多 count 数量的属于槽 solt 的键名。
- 向源节点发送命令原子地将单个键值对迁移到目标节点。
- 重复执行 3、4 步骤,直到所有的键值对迁移到目标节点。
- 向集群中的任意节点发送命令,将槽 solt 指派给目标节点,这一命令会传播给集群中的所有节点。
如果涉及多个槽的迁移,会重复执行单个槽的迁移步骤,在步骤 3 和 4 执行过程中,如果客户端请求了槽 solt 对应的键的操作,若键还在源节点,则进行操作,否则会返回 ASK 错误,指引客户端请求正确的目标节点。
replication 与 failover
Cluster 中的节点也分 master 和 salve。master 用于处理槽,slave 用于复制 master,并在 master 下线时代替下线节点继续处理请求。
Cluster 中的节点会定期向其他节点发送PING命令,来检测对方是否在线。如果半数以上的 master 节点都确定某个节点下线,会向集群中广播一条节点下线通知,并开始进行 failover:
- 下线节点的一个 slave 会被选中
- 对被选中的 slave 执行
SLAVEOF no one的命令,将其设置为 master。 - 新 master 会撤销下线节点的指派槽,并将这些槽重新指派给自己。
- 新 master 向集群广播一条
PONG消息,通知其他节点自己已经成为 master。 - 新 master 开始处理指派槽的客户端请求。
Q&A
说一个喜闻乐见的问题吧,为什么 Redis 是单线程的还那么快,主要有以下几个方面的原因:
- Redis 主要是内存操作
- 数据结构上的优化,降低很多操作的时间复杂度
- 单线程不涉及锁的争用和上下文切换
- 采用多路 I/O 复用模型,可以同时处理多个请求
- CPU 并不是 Redis 的性能瓶颈,单线程就够了
(End)