在上一篇Java并发编程 线程同步机制中提到了几种Java线程同步机制,实际上,Java并发编程的前提是Java的内存模型JMM,这里补一下这方面的知识,对 volatile 、锁和 final 的语义做进一步的理解。
一些概念
Java内存模型(JMM)决定了一个线程对共享变量的修改何时对其他线程可见。从抽象上来说,JMM定义了线程与主存的关系:每个线程都有一个私有的本地内存(并不真实存在,涵盖了对缓存、写缓冲区、寄存器和其他硬件及编译器优化),本地内存中保存了线程读/写共享变量的副本。
顺序一致模型是一个理论参考模型,要求一个线程内的操作完全按程序顺序执行,并且所有线程只能看到单一的执行顺序,每个操作都必须原子执行并对所有线程可见。
JMM在设计时参照了顺序一致模型,但完全实现顺序一致模型会牺牲性能优势,因此做了适当放松:
- 不保证一个线程内的操作按顺序执行
- 不保证所有线程看到一致的执行顺序
- 不保证所有操作原子执行
重排序
执行时为了提高性能,编译器和处理器会对指令进行重排序,常见重排序分为三种:
- 编译器优化的重排序:编译器在不改变单线程语义的前提下可以对程序指令进行重排序
- 指令级并行重排序:处理器采用指令级并行技术(ILP),来实现多条指令的重叠,在没有数据依赖的前提下对指令进行重排序
- 内存系统重排序:处理器采用缓存和读/写缓冲区,加载和存储操作看上去是乱序执行
对于编译器的重排序,JMM的编译器规则会禁止特定的编译器优化的重排序;对于处理器的重排序,JMM则要求编译器在生成字节指令序列时在指定位置插入内存屏障(Memory Barriers)来禁止特定的处理器重排序,来实现一致的内存可见性的保证。
编译器和处理器会在没有数据依赖的前提下进行重排序,但仅仅是单线程环境下的数据依赖,并不能应用到多线程环境。
内存屏障
内存屏障是一组指令,特定的内存屏障可以禁止处理器对特定的读/写操作进行重排序,一般有下面几种:
- LoadLoad Barriers:确保屏障前的 Load 指令先于之后的 Load 指令
- StoreStore Barriers:确保屏障前的 Store 操作对其他处理器可见(刷新到内存)先于之后的 Store 指令
- LoadStore Barriers:确保 Load 操作先于之后的 Store 操作刷新到内存
- StoreLoad Barriers:确保Store操作刷新到内存先于之后的 Load 指令。会使之前的所有 Store 和 Load 指令完成后,再执行之后的指令,需要刷新所有写缓冲的内容到内存中,开销较大
并不是所有的处理器都支持四种内存屏障,由于现代处理器都会使用写缓冲,导致写操作只对当前线程可见,因此都会允许写-读的重排序,StoreLoad Barriers 内存屏障也基本在所有处理器上实现,而其他内存屏障的实现与否则与处理器内存有关,如x86处理器就不支持其他类型的内存屏障。
happen-before
JSR-133内存模型提出了happen-before的概念,用来阐述操作之间的内存可见性。需要注意的是,happen-before 指的是前面的操作结果对后面操作的可见,而不是前面的操作先于后面操作执行。
happen-before 规则一共8条,这里列出重要的几条:
- 程序顺序规则:同一个线程中的每个操作,happen-before于线程之后的任一后续操作
- monitor锁规则:对于一个 monitor 的 unlock 操作,happen-before 于 monitor 的 lock 操作
- 线程结束规则:对一个线程的 join 操作,被 join 的线程中的任一操作 happen-before 于 join 的返回
- volatile变量规则:对一个 volatile 变量的写操作,happen-before 于该变量的后续的读操作
- 传递性规则:如果A happen-before 于 B,B happen-before 于 C,那么A happen-before 于 C
volatile 语义
写 volatile 变量的内存语义:
- 当写一个 volatile 变量时,JMM会把该线程对应的本地内存中的共享变量刷新到主内存
读 volatile 变量的内存语义:
- 当读一个 volatile 变量时,JMM会把该线程对应的本地内存置为无效,线程接下来将从主内存中读取共享变量
为了实现volatile的内存语义,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序,这里JMM采取的是保守策略:
- 在每个 volatile 写操作之前插入一个 StroeStore Barriers
- 在每个 volatile 写操作之后插入一个 StoreLoad Barriers
- 在每个 volatile 读操作之后插入一个 LoadLoad Barriers
- 在每个 volatile 读操作之后插入一个 LoadStore Barriers
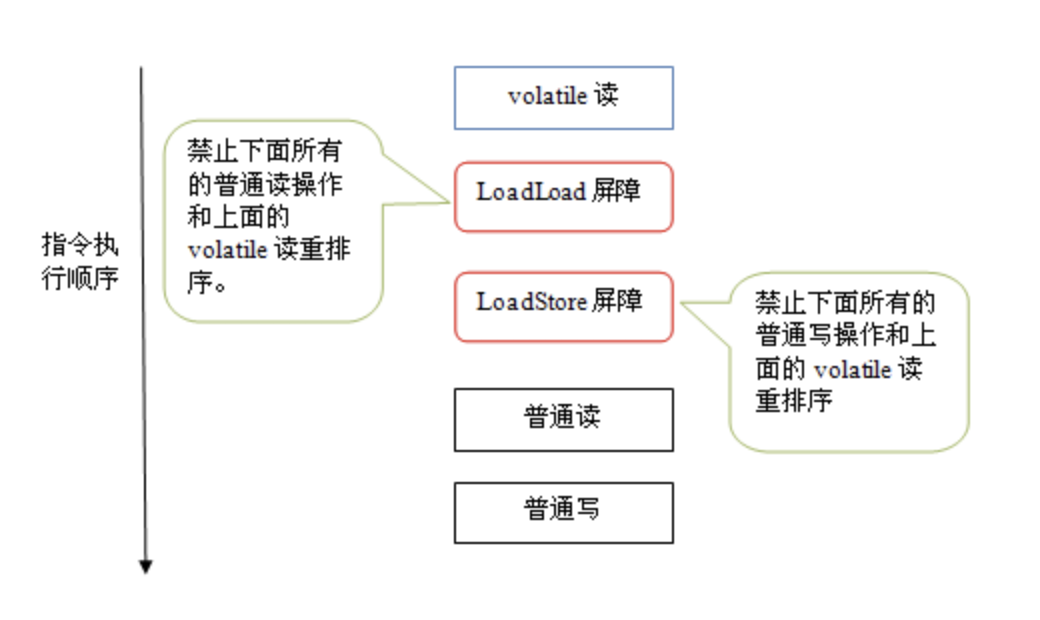
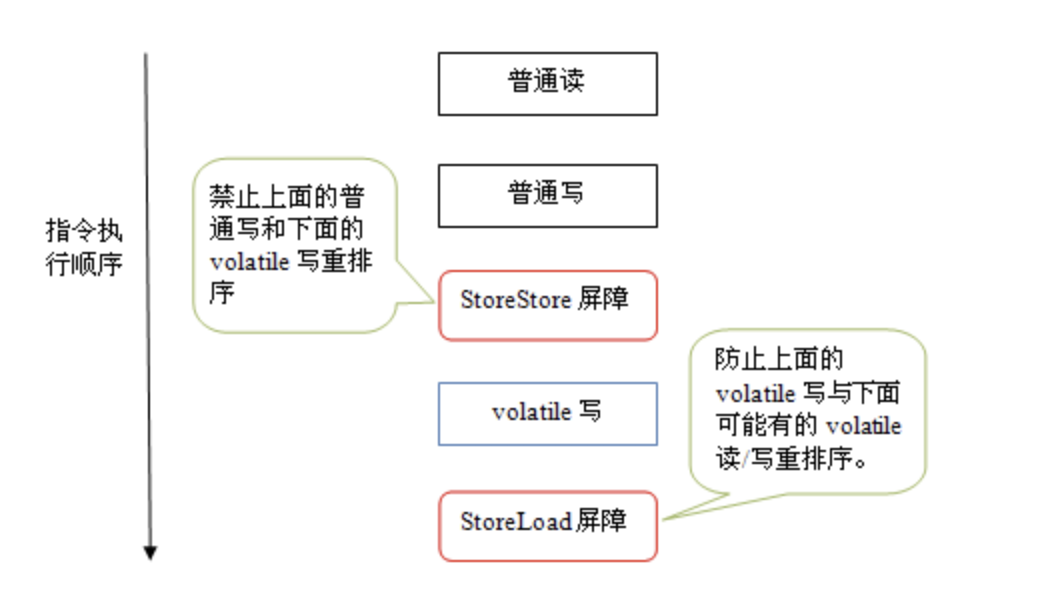
由于内存屏障的存在,编译器和处理器不会对 volatile 读与 volatile 读后面的任意内存操作重排序;不会对 volatile 写与 volatile 写前面的任意内存操作重排序。
内存屏障的插入策略在不通处理器上有不同的实现,如x86处理器就只会在 volatile 写操作之后插入 StroeLoad Barriers
volatile 为什么可以保证 long/double 类型写操作的原子性
首先了解为什么JMM不能保证 long/double 基本类型写操作的原子性:
- 计算机中处理器和内存通过总线传输数据,数据传输过程中的一系列步骤称作总线事务
- 从主存到处理器的传输称作读事务,从处理器到主存的传输称为写事务
在一个事务执行总线事务时,总线会禁止其他处理器与主存进行数据传输,简单来说就是在任意时间点,最多只能有一个处理器能访问内存,因此在同一个事务中的内存读/写操作都是原子性的。
在32位处理器上,JVM会将64位 long/double 类型变量的读/写操作拆分成两个32位的读/写操作来执行,而两个操作可能会被分到不同的总线事务中,不再具有原子性。
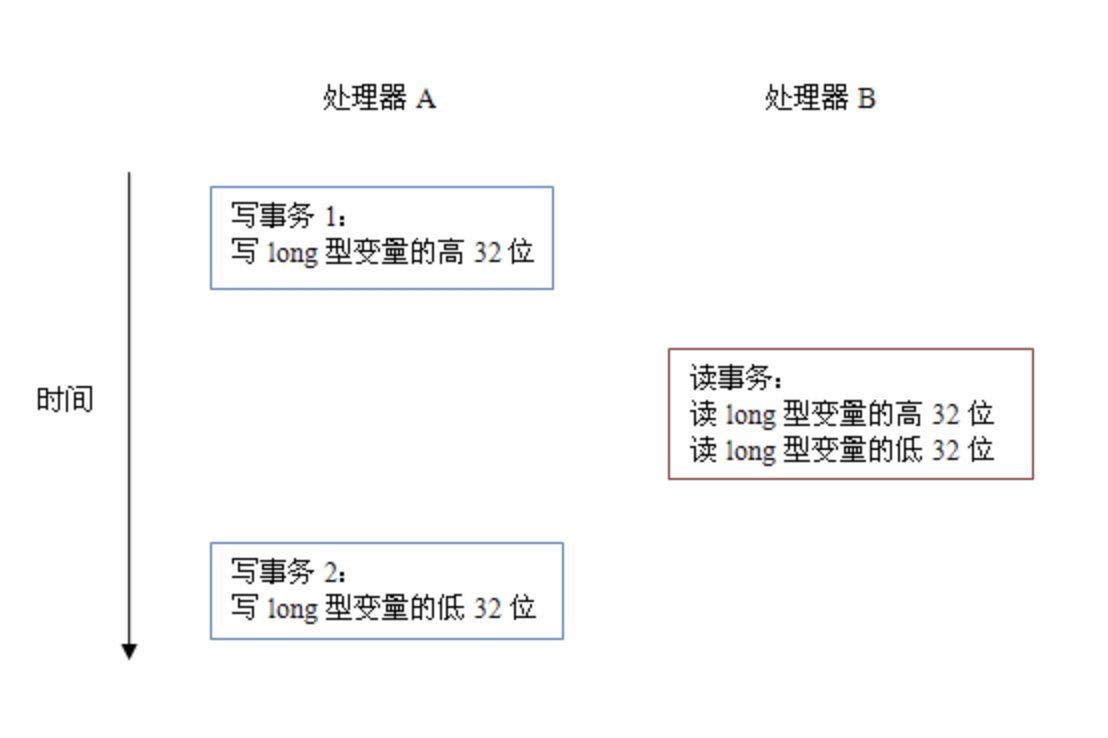
volatile 会在64位变量的读/写操作前后加入特定的内存屏障,保证两个32位的读/写操作完成之前没有新的读/写操作,保证了其原子性。
锁的语义
释放锁的内存语义:
- 当线程释放锁时,JMM 会把该线程对应的本地内存中的共享变量刷新到主内存中
获取锁的内存语义:
- 当线程获取锁时,JMM 会把该线程对应的本地内存置为无效,临界区内的代码必须要在主存中获取共享变量的值
锁的释放与 volatile 写有相同的内存语义,锁的获取与 volatile 读有相同的内存语义。
下面以ReentrantLock为例了解锁的内存语义的实现。ReentrantLock的实现依赖AbstractQueuedSynchronizer(AQS),AQS中使用一个整型 volatile 变量(state)来同步状态。
- 公平锁获取锁时,首先会去读这个 volatile 变量;非公平锁获取锁时,会通过 CAS 更新这个变量。
- 释放锁时,会在最后写这个 volatile 变量
CAS同时实现了 volatile 变量读/写的内存语义,实现方式为 native 方法会在多处理器环境下为
cmpxchg指令前加上lock前缀,这个前缀会禁止该指令与之前和之后的读和写指令重排序,并且把写缓冲区中的所有数据刷新到内存中。这里不做展开。
根据 happen-before 的传递性规则,释放锁的线程在写 volatile 之前可见的共享变量,在获取锁的线程读取同一个 volatile 变量后对获取锁的线程可见。
final的语义
对于 final 域的变量,编译器和处理器遵循下面两个重排规则:
- 在构造函数中对一个 final 域的写入,与随后把这个被构造的对象赋予一个引用变量,这两个操作不能被重排
- 初次读取一个包含 final 域的对象的引用,与随后读这个 final 域,这两个操作不能被重排
对于 final 修饰的普通类型:
- JMM 禁止将写 final 域的操作重排到构造函数之外,通过在写 final 域的操作之后,构造函数 return 之前插入一个 StroeStore 内存屏障
- JMM 禁止将初次读 final 域的操作与初次读对象引用的操作进行重排序,通过在读 final 域的操作之前插入一个 LoadLoad 内存屏障
对于 final 修饰的引用类型,则会增加下面的规则:
- JMM 禁止将写 final 引用对象的成员域的写入,与随后在构造函数外将对象的引用赋予一个引用变量,这两个操作不能被重排序
写 final 域的重排序规则可以确保:在引用变量为任意线程可见之前,该引用变量指向的对象的 final 域已经在构造函数中被正确初始化过了。但如果对象在构造函数内逸出,则不能保证 final 域被初始化,因为构造函数内的指令可以被重排序。
(End)
参考资料: InfoQ 程晓明 深入理解 Java 内存模型