饿厂于17年顺利完成了异地多活改造。改造的目的一是当时每天的订单量已经达到千万级,北京的机房无法扩容;二是机房级别的故障时有发生,每次都会造成很大损失,需要地理级别的容灾。上篇文章的最后已经提到过,异地多活的复杂度和实现成本都是很高的,饿厂也不例外,除了中间件的建设,各业务方都需要进行多活改造。作为在饿厂搬了一年砖的业务小白,这里整理一下饿厂异地多活建设中所解决的问题和解决问题的方法。
要实现异地多活,需要在不同地理位置的两个机房有独立的Service集群和存储集群,同时为了进行故障切换,每个机房的存储单元要有全量数据,相对简化下的架构图如下:
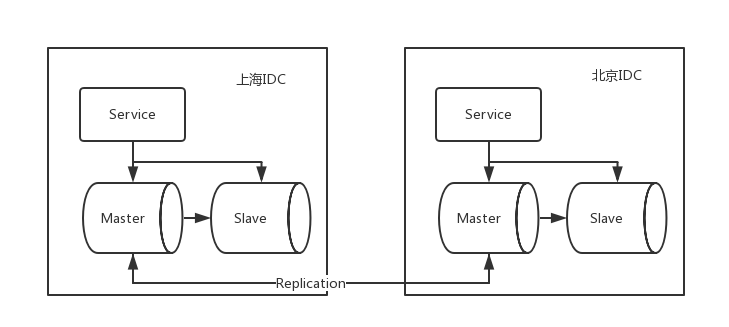
看似简单,但异地多活引入了很多棘手的问题:
- 如何分配流量到不同的IDC
- 多存储集群引入了multi-master,如何解决multi-master的写入冲突
- 如何进行机房间的数据同步
- 数据同步存在延迟,如何应对对数据强一致性要求较高的业务
- 故障转移(failover)时如何解决写入与复制的数据冲突
我们看一下饿厂给出的解决方案。
流量sharding - API Router
异地多活的流量分配可以简单用id来划分,但用id划分会造成很多的跨机房调用,此外由于外卖业务的特殊性,商户-骑手-用户都处于同一地理级别,因此饿厂利用经纬度将全国划分为很多的地理围栏,主要以省为单位,接壤部分进行微调,不同地理位置的流量打入确定的IDC。
shardingKey是APP改造后携带的分流标签,核心是地理位置,也有很多业务标签如订单id、商户id等。GZS(Global Zone Service:全局状态协调器)会将APP客户端请求携带的shardingKey根据地理围栏计算成shardid,再根据shardid查询流量该打入哪个IDC。
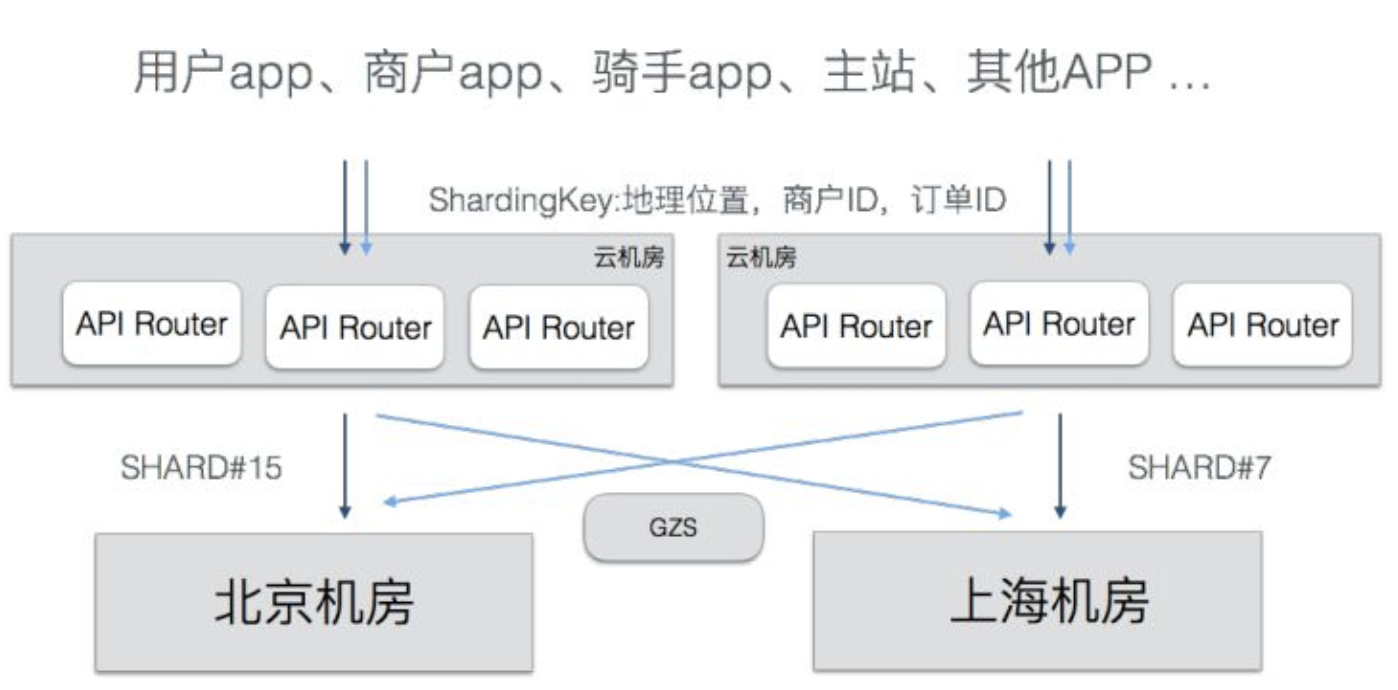
饿厂开发了API Router层负责处理流量路由,部署在多个公有云中,它是流量的最上游,通过查询GZS将流量打入正确的IDC。
multi-master写入冲突 - DAL
两个IDC必然要有两个master,解决multi-master下的写入冲突最为行之有效的办法是,对于一条记录,只能有一个master可以写入。
DAL(Data Access Layer:数据访问)层负责处理这部分逻辑。判断流量该打进哪个IDC与判断一条记录可以写入哪个master是一样的道理,DAL也会请求GZS判断路由规则,将不属于当前机房的流量拒绝。
对于不同机房的主键冲突,饿厂的解决方案是两个机房采用相同的步进长度,但设定不同的offset。
replication - DRC
DRC(Data Replication Center)用来实现MySQL的双向复制,解析MySQL的binlog并将binlog event转化为自己的数据格式(更小),通过JDBC写入另一个机房的服务器,整体延迟在1s以下。
上面提到通过确保一条记录只能写入一个master来解决写入冲突,但实际上冲突是无法避免的(如shardingkey缺失的行记录),饿厂通过给所有表增加一个业务方不感知的时间戳字段check_time,当发生写入冲突时根据时间戳保留最新的记录。
强一致 - GZ
对于一些不能接受DRC延迟的业务(如注册),可以通过GZ(Global Zone)实现强一致性。
GZ模式下只有一个机房的数据库支持写入,类似于主从模式,同时DAL支持读操作绑定主库,实现强一致性。在进行failover切换时,将另一个机房的数据库设置为主库。GZ的一个问题在于跨机房读写的延迟较高,高QPS业务需要避免使用或通过缓存解决延迟问题。
failover时的一致性
由于双机房的数据同步存在延时,当故障发生时,会有一部分来不及同步的数据,此时如果切换到新机房发生新的写操作,会导致数据的乱序写,且无法修复。这时根据CAP理论,如果要保证一致性的话,就要暂时放弃可用性,方法是:failover时锁定一部分老数据的update操作(会直接报错),直到数据同步完成,在此期间新数据是可以插入的。
饿厂的具体shard切换方法如下:
- 同样利用上面提到过的时间戳check_time,发生切换时记录一个当前时间reshard_at。
- 老机房完全停止写入。
- 新机房check_time在reshard_at之前的数据禁止写入。
- DRC复制数据的check_time追上了reshard_at,新机房开启写入。
最终架构如下:
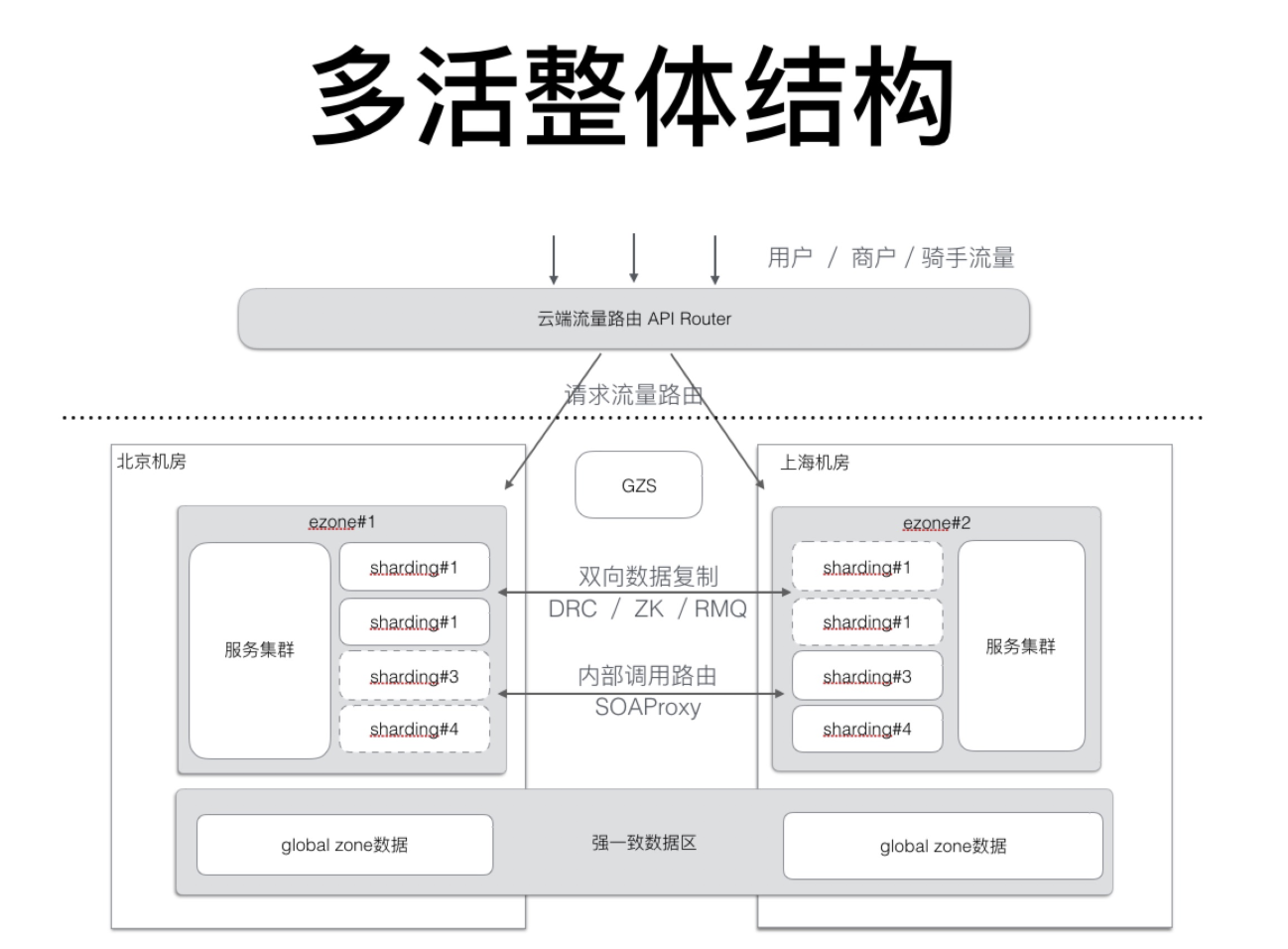 饿厂对于异地多活中的难点问题的解决方案大体上就是这些,上面的解决方案中所提到的中间件大部分都是一笔带过,其中有各种难点问题需要解决,这里就不再赘述了。有兴趣可以查看相应博文。
饿厂对于异地多活中的难点问题的解决方案大体上就是这些,上面的解决方案中所提到的中间件大部分都是一笔带过,其中有各种难点问题需要解决,这里就不再赘述了。有兴趣可以查看相应博文。
(End)
参考资料: