如今,各类Web架构竞相辉映,集群,微服务,异地多活,分布式等名词层出不穷,这些东西是你日常工作的一部分,或者至少也是不少技术类文章中的热词,于开发人员来讲并不生疏。但这些东西是怎么来的,为了解决什么样的问题,确是值得思索的命题。
其实,如今各类成熟的Web服务架构并非一蹴而就的,而是随着服务规模的不断增大而演化过来的。刚来时可能服务的用户并不多,业务线也很少,这时的应用程序、数据库、静态文件可能都在一台服务器上,代码能够正常运行即可满足要求。而随着用户量的增加,一台服务器就无法满足需求了,流量的上升导致访问速度越来越慢,数据量的增大导致储存空间的不足,这时候就会将应用程序、数据库和文件服务进行分离,分别放在三台服务器上。之后,随着规模进一步加大,越来越多的问题暴露出来:为了解决应用程序服务的压力,出现了代理服务器、集群和负载均衡的概念;为了解决数据库压力,出现了读写分离、缓存服务器和分布式数据库的概念;为了解决文件服务器的压力,出现了CDN加速的概念;为了应对冗杂的业务线,出现了微服务和职能划分的概念……服务架构也慢慢趋于成熟变成了现在的模样。
本文就简单介绍下大规模Web服务发展过程中出现的一般性问题和解决方案。
大规模服务要解决的问题
与只有几台服务器的小规模服务相比,大规模服务要解决的问题主要存在与一下几点:
-
负载:如何应对一台服务器无法承担的流量压力。
-
冗余性:如何保证在某些服务器出现故障时系统仍然能维持正常运行。
-
低成本运维:如何在多台服务器中定位和发现问题,如何监控服务的健康性。
-
开发方式:如何多部门,多开发人员协同开发。
本文将主要围绕前两点讨论,关于运维方面的知识暂不做过多介绍。
负载
如开篇所讲,Web服务的基础设施一般由几部分组成:
-
代理服务器:负责接收和分发请求,处理负载均衡。
-
进程服务器:处理业务逻辑和计算,产生CPU负载。
-
数据库服务器:处理数据读写,产生I/O负载。
CPU负载
CPU负载产生的原因很简单,请求增加带来系统运算处理能力的加大,单位时间内需处理的任务数量加大带来CPU负载上升。
由于应用进程服务每个服务相互独立,因此解决CPU负载的方式简单通用,即扩展服务器,但扩展方式稍有区别:
-
横向扩展:通过增加服务器的数量来提高整体的处理能力。
-
纵向扩展:通过提高硬件性能来提高处理能力。
考虑到性价比,目前横向扩展的应用较为广泛。
I/O负载
相对于CPU负载,I/O负载陈胜的云因稍微复杂,解决方式也略微棘手。
进程读取磁盘中数据的一般过程如下:
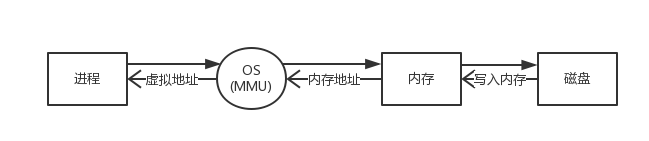
磁盘到内存的读写速度是很慢的:
-
查找速度:由于数据的搜索是磁盘旋转的物理动作,与在内存中查找数据的速度相比慢了10^5倍。
-
传输速度:磁盘到内存的总线传输速度比内存到CPU的总线传输速度慢了10^2倍。
页面缓存
操作系统会对磁盘上的文件进行页面缓存,即内核分配过的内存不会释放,而是会一直保留下来,但内存容量毕竟有限,会遵照下面的缓存策略对磁盘进行缓存:
-
LRU(Leasr Recently Used):最近使用的数据会被缓存,即新的数据会取代老数据在内存中的位置。
-
内存有空闲时就缓存:内存会在空闲时自动缓存磁盘中的文件(注:重启之后所有的页面缓存会失效,这也是为什么数据库服务器在重启之后需要cat所有数据库文件)。
当数据量提高时,内存的容量开始小于数据库大小,由此产生了大数据量I/O负载的痛点:无法都在内存中进行计算。
针对这一原因,I/O负载的解决思路如下:
-
减小数据大小:采用压缩等算法。
-
扩展:如果数据量不大,可采用纵向扩展,即增加内存;横向难度较高,考虑局部分散。
-
降低读取次数:一些对数复杂度的算法,批量数据集中读取等技巧。
MySQL局部横向扩展
与应用程序的简单横向扩展不同,数据库的横向扩展并不能通过增加服务器数量的方式来提高处理能力,因为单纯将数据复制,不能缓存到内存的部分依然不能缓存,这是需要考虑局部的横向扩展,这里以Mysql为例做简单介绍。

分割
既然一台机子(一个数据库)上的数据量无法分割,就将数据库分割到多台服务器上。分割的方式有很多种,最简单的就是以表为单位进行分割,目前很多企业选用这种方式,将不同的表分散在不同的数据库服务器中,这样做的优势在于成本较低,对业务的侵入性较小,开发人员唯一需要关注的就是不要在业务代码中使用join查询而用where in作为替代。
读写分离
在分割的基础上,要对同一张表的服务器再进行横向扩展就要采用读写分离的策略,即在多台服务器(一般为4的倍数)中选取一台作为master,通过负载均衡服务器或代理将所有update的更新查询发给master,把只有select等读取查询发给其余的slave,通过master和slave的复制实现数据同步。
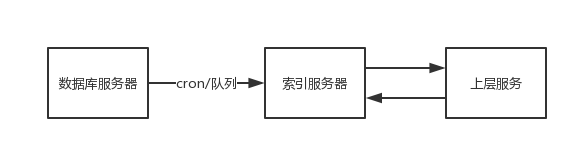
索引服务器
当数据吞吐量远超过RDBMS的能力,即无论采取什么方式都无法优化大数据量读取或优化起来成本较高时,可以考虑在数据库服务器和上层服务之间架设索引服务器(如elasticsearch),定时同步数据库数据与索引服务器数据,上层在读取数据时可以直接从索引服务器中读取。
系统负载调优
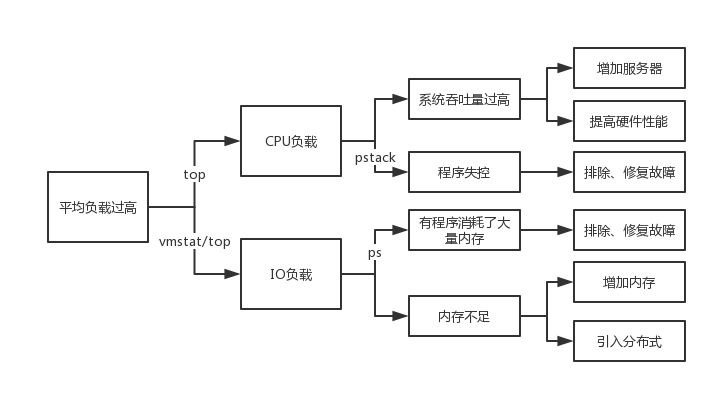
当规模提高带来请求相应变慢时,开发者的首要直觉都是我的系统“卡了”,这时就需要系统调优来将你的系统服务恢复正常,即找到问题并排除之。
系统调优的核心点在于发现负载来源于CPU还是I/O,思路基本如下图。
冗余
服务的冗余是为了解决Web服务负载横向扩展带来的安全问题,即需要保证在横向扩展中的一台服务器出现故障时整体服务的运行不受影响。目前业内做法是在整体服务处理能力最大值的70%下平稳运行,即如果服务负载达到阈值的70%就需要加大服务器的冗余数量。
应用程序服务器
应用程序服务器的冗余非常简单,只需要在负载均衡服务器做好失败转移和失败恢复即可,即如果服务器出现故障就将其剔除出集群,待故障处理完毕之后将其加入集群。
数据库服务器
slave服务器
同应用程序服务器一样,只需要在上层的负载均衡服务器或代理层处理即可,但有一点需要注意,由于数据库服务器出现故障之后存在数据恢复和复制的问题,需要停掉一台正常服务器进行恢复,也可能存在主从切换的问题,因此在进行冗余时master和slave的比例一般为1:3。
master服务器
master服务的冗余相对就困难许多,目前业内的一般做法是对不同master服务器之间进行双向复制,以保证master的冗余。但如果在一方写入的瞬间领一台服务器停机,就会出现数据不一致的风险,结合Web服务自身特点,可以暂时忽略风险,优先保证性能。
Web服务的基础设施
由于性价比的考虑,越来越多的Web服务开始采用其他专业提供基础服务设施的企业提供的资源搭建。
目前服务的基础设施搭建有两种思路:
-
垂直结合:从上层到底层服务全部自行构建。
-
水平分散:不同模块采用不同企业的服务。
虚拟化技术
所谓虚拟化技术就是将各类实体资源(如服务器)进行抽象,再重新分配到实体资源中,即两个服务器可以在一个机器上运行。如一个服务器如果有I/O空闲,就可以引入数据库服务器,如果存在CPU空闲,则可以引入应用程序服务器。这种技术一定程度上提高了基础设施的利用率。
(End)